 Image credit: Dr Ayana Elizabeth Johnson
Image credit: Dr Ayana Elizabeth Johnson
My main research theme is learning from simulations, both in Climate Science and in Astronomy. I am broadly interested in model discovery, causal structure learning, representation learning, and uncertainty quantification. Even more broadly, I am constantly trying to figure out what goes in the diagram on the left for me.
These are some of the things I am up to right now:
These are some of the things I am up to right now:
|
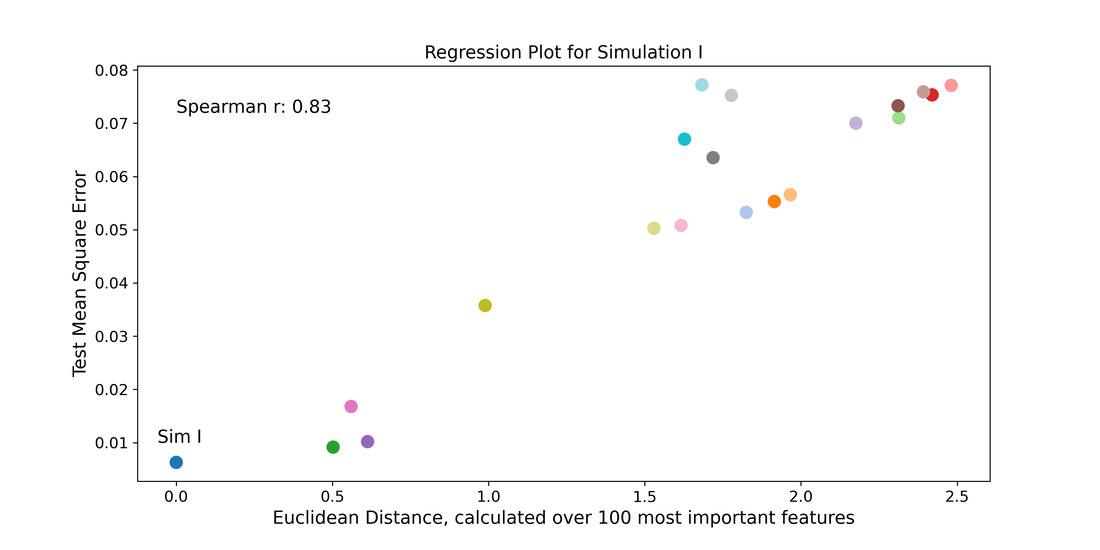
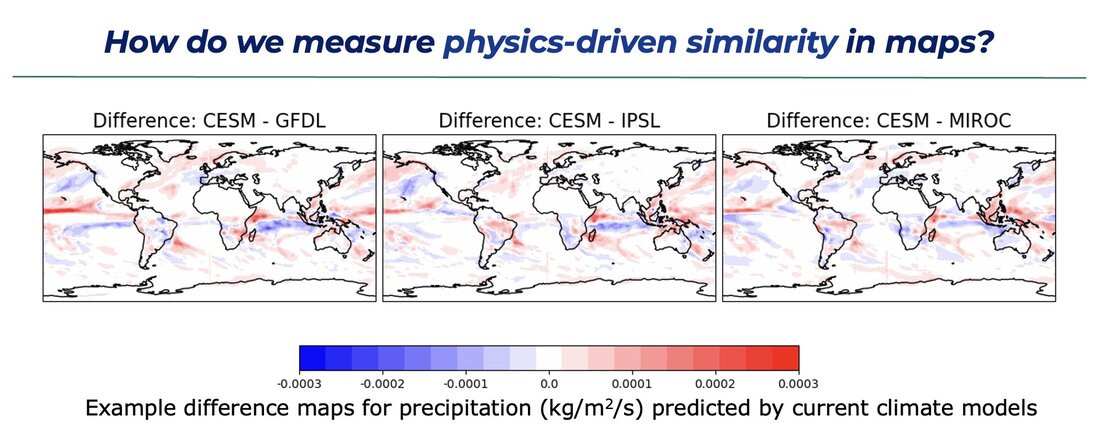
In my first climate project, we are planning to develop and test new custom metrics to assess similarity in climate maps in a way that connects with the physical differences of global models. An example for precipitation maps is shown on the right. I will be hiring a postdoc in 2024 to work on this problem!
|
|
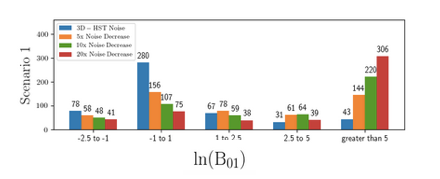
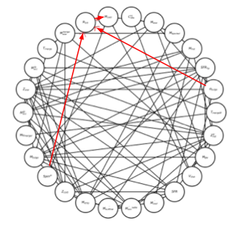 The final version of this figure will summarize our causal analysis with Directed Acyclic Graphs.
Credit: S. di Gioia.
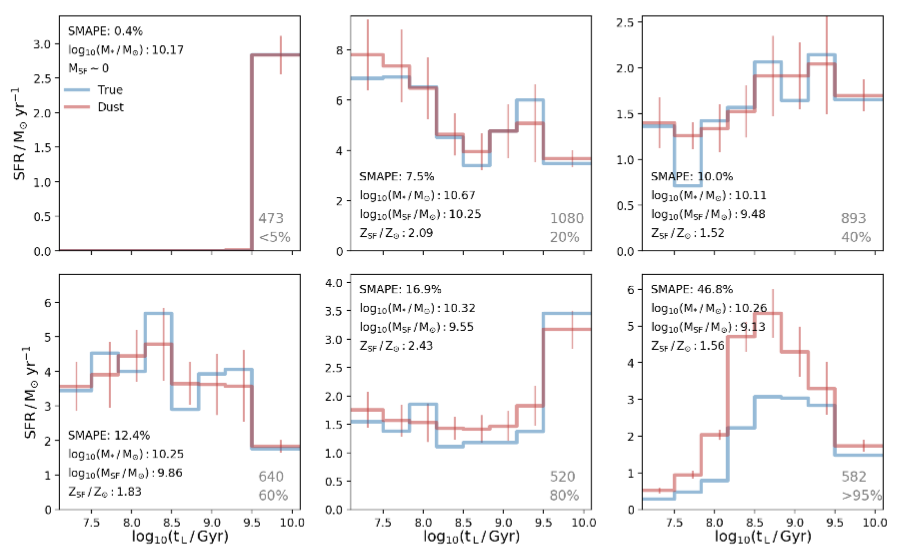
The final version of this figure will summarize our causal analysis with Directed Acyclic Graphs.
Credit: S. di Gioia.
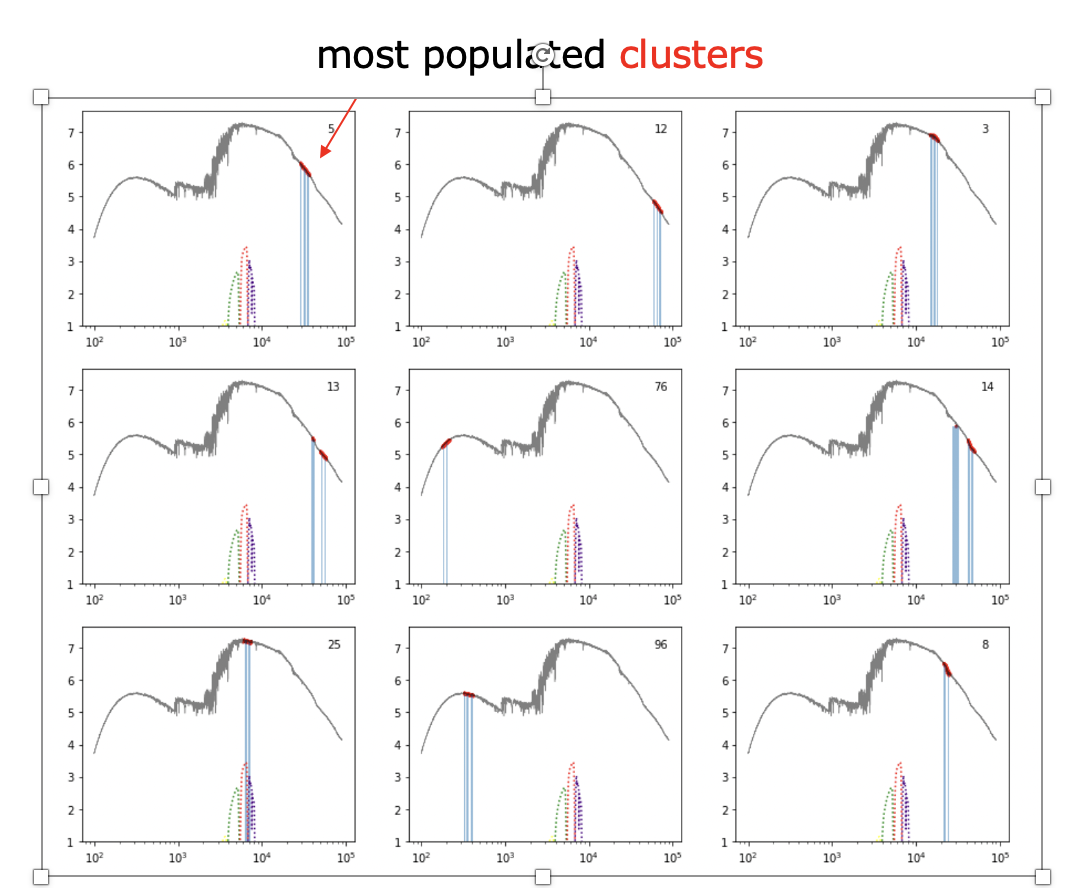
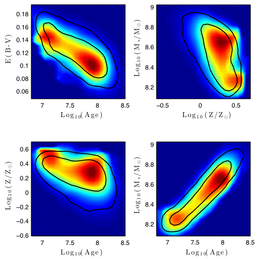
In another ongoing project, I am working with Festa Buçinca and Ari Maller to test a pipeline to discover hypotheses for physical models. We are looking at whether we can recover a model for the origin of galaxy sizes in semi-analytic model of galaxy formation, using feature ranking techniques to figure out what variables are important, and symbolic regression to generate our hypotheses. Spoiler alert: it's really hard! Together with Serafina di Gioia and Roberto Trotta, we are trying to figure out if causal structure learning (left) can help.